Fonctionnement des crawlers de Google
Chaque jour, des milliards de pages web s’ajoutent ou évoluent sur Internet. Pour offrir aux internautes des résultats pertinents, le moteur de recherche Google s’appuie sur un processus complexe d’exploration et d’indexation, orchestré par des logiciels appelés « crawlers » ou robots d’exploration. Parmi eux, Googlebot joue un rôle central, en parcourant méthodiquement le web pour identifier et analyser le contenu susceptible d’être intégré dans l’index Google. Comprendre le fonctionnement de ces crawlers est essentiel, autant pour les créateurs de contenu que pour les spécialistes du SEO, afin d’optimiser la visibilité des sites dans les résultats de recherche. Ce processus influence directement le référencement, le classement PageRank, et façonne l’accès à l’information dans l’écosystème numérique actuel.
Dans un monde numérique toujours plus dynamique et concurrentiel, la maîtrise des mécanismes d’exploration de Google n’est plus réservée aux seuls développeurs. La compréhension de ces bots et de leur interaction avec les pages web est désormais un levier stratégique pour améliorer la qualité de l’indexation et l’efficacité du SEO. Des notions telles que les sitemaps, les fichiers robots.txt, ou encore le rendu JavaScript se révèlent déterminantes pour s’assurer que le contenu d’un site soit non seulement découvert mais aussi correctement analysé par les crawlers de Google.
Ce panorama méthodique dévoile comment Googlebot et ses congénères scannent le web de manière continue, adaptée à la fréquence des mises à jour des sites, tout en respectant les contraintes techniques des serveurs. Entre les différentes versions du crawler pour les environnements desktop et mobile, et les mises à jour régulières du moteur d’exploration lui-même, Google cherche à garantir une indexation la plus complète, pertinente, et à jour possible. Cette dynamique implique aussi une vigilance accrue : la gestion du budget de crawl, l’extraction du contenu, et la prévention des erreurs techniques sont des enjeux clés qui conditionnent le succès d’une stratégie SEO performante.
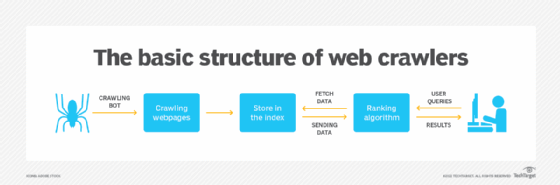
Googlebot : le moteur principal des crawlers de Google expliqué en détail
Googlebot est la pierre angulaire de l’exploration web par Google, constituant le logiciel d’exploration ou « crawler » par excellence du géant américain. Son objectif est d’explorer continuellement l’immense réseau de pages web publiques pour découvrir, analyser et sélectionner des contenus destinés à être indexés dans le moteur de recherche. Il ne s’agit pas simplement d’un robot automatisé qui navigue sans distinction : Googlebot suit avec méthode les liens d’une page à une autre pour parvenir à une couverture exhaustive et pertinente. Ce processus d’exploration est à la base même de la constitution de l’index de Google, véritable catalogue où chaque page référencée est analysée selon ses caractéristiques SEO et son contenu.
Le fonctionnement de Googlebot repose sur trois grandes fonctions clés :
- Crawling : La découverte et la lecture des pages web en suivant les hyperliens.
- Indexation : L’analyse et le stockage des informations extraites des pages dans l’index Google.
- Ranking : La phase de classement des pages dans les résultats de recherche, qui est prise en charge par des algorithmes distincts, et non directement par Googlebot.
Il est important de noter que Googlebot existe en plusieurs versions. En effet, il y a une version qui simule la navigation depuis un ordinateur de bureau (desktop) et une autre adaptée à la navigation mobile. Cette double configuration est devenue essentielle avec la généralisation de l’index mobile-first, où Google privilégie l’analyse du contenu selon la version mobile des sites. Certains sites peuvent ainsi être explorés à la fois par la version desktop et mobile du crawler, mais dans la plupart des cas, l’accent est mis sur la version mobile à cause des comportements actuels des internautes.
| Version de Googlebot | Simule | Utilité principale |
|---|---|---|
| Googlebot Desktop | Utilisateur sur ordinateur de bureau | Exploration traditionnelles des sites non adaptés mobile |
| Googlebot Mobile | Utilisateur sur smartphone ou tablette | Indexation mobile-first, analyse du contenu mobile |
Les avancées techniques dans le moteur de Googlebot pour un crawl plus intelligent et rapide
Depuis quelques années, Googlebot a connu des évolutions majeures visant à moderniser son moteur d’exploration. Jusqu’en 2019, la version du navigateur embarqué dans Googlebot reposait sur Chrome 41, datant de début 2015. Cela posait problème, notamment pour les sites modernes utilisant des frameworks JavaScript avancés et des fonctionnalités récentes qui n’étaient pas reconnues par cette vieille version.
Pour pallier cette limitation, Google a basculé vers un moteur d’exploration « evergreen » — toujours à jour — basé sur la version actuelle de Chromium. Cette transition a profondément amélioré la capacité d’exécution de JavaScript et la gestion des interfaces web riches, rendant le crawler capable de rendre, analyser et indexer des pages comme le ferait un navigateur moderne. Il peut désormais interpréter avec précision des fonctions essentielles comme ES6, les Web Components, ainsi que le lazy-loading avec IntersectionObserver.
- Support JavaScript moderne : Exécution plus complète, moins de reverifications manuelles.
- Meilleur rendu : Pages analysées avec un rendu graphique complet pour prendre en compte le contenu dynamique.
- Optimisation du crawl : Analyse accélérée, avec un budget d’exploration adapté pour ne pas surcharger les serveurs.
Cela correspond à un changement fondamental dans la manière dont Googlebot traite une page : en 2 temps — d’abord le crawl, puis le rendu complet. Cette double phase permet d’avoir une compréhension plus fine du contenu et de son contexte, surtout quand ce dernier s’appuie fortement sur du JavaScript dynamique. Les référenceurs doivent donc s’assurer que les scripts ne bloquent pas l’exploration ou ne dégradent pas l’expérience utilisateur côté crawler.
Le tableau ci-dessous met en lumière quelques bénéfices clés du Googlebot moderne :
| Avantage | Description | Impact SEO |
|---|---|---|
| Interprétation avancée du JavaScript | Support étendu des normes ES6+ sans nécessité de transpiling | Meilleure indexation du contenu dynamique |
| Compatibilité mobile renforcée | Rendu identique à un navigateur mobile récent | Optimisation pour l’index mobile-first |
| Réduction des erreurs d’exploration | Charge et analyse plus efficace, limitation des erreurs 4xx/5xx | Meilleure visibilité et confiance du moteur |
Pour découvrir les détails techniques et les conseils pour optimiser l’indexation face à ces avancées, les articles sur Ranktracker ou Respoweb restent des références précieuses.
Le rôle des sitemaps, robots.txt et autres protocoles d’exploration dans le crawl Google
Les crawlers de Google ne parcourent pas le web de manière anarchique : ils respectent des consignes et protocoles pour optimiser leur passage et préserver les ressources des serveurs. Parmi les outils majeurs pour guider Googlebot, on retrouve les fichiers sitemaps et robots.txt.
Les sitemaps agissent comme une carte signalant les URL essentielles à explorer, la fréquence de leurs mises à jour, leur priorité, et d’autres informations précieuses. Un sitemap bien structuré aide le crawler à détecter rapidement les pages nouvelles ou modifiées, maximisant ainsi leur indexation rapide et pertinente.
Le fichier robots.txt joue un rôle inverse, servant à spécifier les chemins que Googlebot ne doit pas parcourir. Il permet d’éloigner les crawlers de contenus sensibles ou inutiles du référencement, évitant ainsi l’exploration et l’indexation superflues qui peuvent nuire au budget de crawl global d’un site. La proper gestion de ce fichier est précieuse dans la stratégie SEO pour éviter par exemple le crawl sur des pages satellites de faible valeur ou dupliquées.
- Permettre ou bloquer l’accès à certaines sections du site.
- Optimiser la fréquence du crawl selon la valeur ou le caractère dynamique des pages.
- Gérer le budget de crawl pour améliorer la profondeur d’exploration des pages clés.
- Réduire la charge serveur et éviter que Googlebot surcharge les ressources.
- Faciliter l’exploration des ressources essentielles (images, vidéos) référencées dans le HTML.
Voici un tableau simplifié des directives types que l’on peut donner aux crawlers dans le fichier robots.txt :
| Directive Robots.txt | Effet | Exemple pratique |
|---|---|---|
| User-agent: * | Application à tous les bots | Interdire l’accès à /admin/ pour tous |
| Disallow: /private/ | Blocage de ce dossier | Empêchera l’exploration des pages privées |
| Allow: /public/ | Autorisation d’accès | Permet au bot d’explorer les pages publiques même sous Disallow précédent |
| Sitemap: URL | Indique l’emplacement du sitemap | Aide le crawler à découvrir plus facilement les pages à indexer |
Pour optimiser ces protocoles, il est conseillé de consulter des guides spécialisés comme celui ci sur les robots txt en seo. Ces ressources offrent des méthodes concrètes pour maximiser l’efficacité du crawl tout en préservant la santé technique des sites.
Comprendre le budget de crawl et la fréquence d’analyse des sites par Googlebot
Le concept de « budget de crawl » est fondamental pour saisir la manière dont Googlebot décide quand et à quelle intensité visiter un site web. Ce budget correspond à la quantité de ressources que Google est prêt à allouer à l’exploration d’un site pendant une période donnée.
Plus le site est stable, sain, et intéressant pour le moteur — avec un contenu régulièrement mis à jour, relevant pour les utilisateurs — plus Googlebot assignera un budget important permettant une exploration plus fréquente et plus poussée. Inversement, un site présentant des erreurs fréquentes, des délais de serveur longs, ou une faible valeur pour l’algorithme, sera exploré moins intensément pour éviter de gaspiller des ressources ou surcharger inutilement l’hébergement.
- Les sites d’actualités ou e-commerce à fort renouvellement ont un crawl fréquent.
- Les blogs ou sites statiques peuvent voir leur fréquence d’exploration réduite.
- Les erreurs HTTP (404, 500) font diminuer la confiance de Googlebot et le budget alloué.
- Des règles dans le fichier robots.txt peuvent limiter artificiellement le crawl.
- La vitesse serveur et temps de réponse favorisent un crawl plus dense et efficace.
Le crawl ne se fait jamais en une seule fois sur tout un site, mais de manière progressive, avec un test de charge qui augmente jusqu’à ce que des erreurs apparaissent, avant de ralentir pour prendre en compte la « santé » du serveur. Cette approche évite les interruptions spammées et assure que les pages essentielles reçoivent une attention prioritaire. Un site peu exploité aura donc sa visibilité pénalisée car moins de pages seront indexées ou à jour dans l’index.
| Critère Affectant le budget de crawl | Conséquence | Impact sur le SEO |
|---|---|---|
| Qualité de l’hébergement | Temps de réponse rapide favorisé | Meilleure fréquence et profondeur d’exploration |
| Fréquence des mises à jour du contenu | Crawl plus fréquent | Indexation rapide des nouveautés |
| Présence d’erreurs serveur | Réduction du budget pour éviter surcharge | Perte de visibilité de certaines pages |
Pour approfondir ce sujet clé en SEO technique, Lire l’article sur le crawling-et-seo : une analyse méthodique et des conseils pratiques pour optimiser ce paramètre souvent méconnu mais stratégique.

Détection de Googlebot et contrôle de l’accès pour une meilleure gestion SEO
Savoir quand et comment Googlebot visite un site est une donnée fondamentale pour le webmaster souhaitant mesurer et optimiser son référencement. Chaque requête envoyée par Googlebot inclut un « user-agent » qui permet d’identifier le bot et de différencier ses visites de celles d’autres robots ou utilisateurs. Cependant, ce « user-agent » peut être facilement usurpé, ce qui complexifie la traçabilité.
Pour éviter les contrefaçons, Google recommande de procéder à des vérifications avancées comme la recherche DNS inversée ou l’analyse des plages IP publiques officiellement dédiées à Googlebot, mises à disposition depuis 2021. Ces validations sécurisent la certitude que l’exploration est bien effectuée par Google, et non par des crawlers malveillants.
- Utiliser les log serveur pour analyser les visites Googlebot.
- Valider les IP via DNS inversé pour authentifier le crawler.
- Configurer le fichier robots.txt pour autoriser ou bloquer Googlebot selon les besoins.
- Recourir au rendu dynamique (dynamic rendering) pour proposer du contenu adapté au crawler.
- Surveiller les erreurs d’accès et les refuser si elles entravent l’indexation.
Il est aussi possible d’empêcher partiellement ou totalement l’accès de Googlebot à certaines zones stratégiques, mais cela doit s’effectuer avec prudence afin de ne pas compromettre la performance SEO globale.
FAQ sur le fonctionnement des crawlers de Google
| Question | Réponse |
|---|---|
| Qu’est-ce que Googlebot ? | Googlebot est le principal crawler de Google, chargé d’explorer le web pour découvrir et indexer des contenus publics afin de les faire apparaître dans les résultats de recherche. |
| Comment Googlebot gère-t-il le contenu JavaScript ? | Depuis sa mise à jour vers un moteur evergreen, Googlebot exécute JavaScript comme un navigateur moderne, ce qui améliore l’analyse des contenus dynamiques. |
| Quelle est l’importance du fichier robots.txt ? | Il guide le crawl en autorisant ou bloquant l’accès à certaines sections, ce qui optimise le budget d’exploration et améliore la qualité globale de l’indexation. |
| Comment vérifier qu’une requête provient bien de Googlebot ? | La meilleure méthode est de réaliser une recherche DNS inversée sur l’adresse IP et de vérifier qu’elle appartient aux plages officielles de Google. |
| Que faire si un site est peu exploré par Googlebot ? | Il faut améliorer la qualité technique du site, accélérer le temps de réponse, actualiser régulièrement le contenu et utiliser les Sitemaps pour mieux guider l’exploration. |